I can honestly state there is already one that folks are using; I would suggest DARPA should assess it and maybe acquire it. As it would give them a jump start and they can enhance it for their own needs.
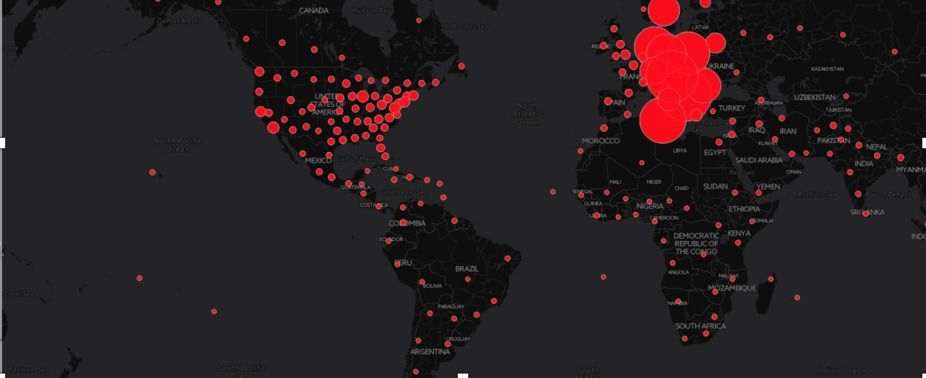
In today’s data-rich world, companies, governments and individuals want to analyze anything and everything they can get their hands on – and the World Wide Web has loads of information. At present, the most easily indexed material from the web is text. But as much as 89 to 96 percent of the content on the internet is actually something else – images, video, audio, in all thousands of different kinds of nontextual data types.
Further, the vast majority of online content isn’t available in a form that’s easily indexed by electronic archiving systems like Google’s. Rather, it requires a user to log in, or it is provided dynamically by a program running when a user visits the page. If we’re going to catalog online human knowledge, we need to be sure we can get to and recognize all of it, and that we can do so automatically.
How can we teach computers to recognize, index and search all the different types of material that’s available online? Thanks to federal efforts in the global fight against human trafficking and weapons dealing, my research forms the basis for a new tool that can help with this effort.