Free field theory.
free field.
quantum field.theory.
quantum field theory in a nutshell pdf.
quantum field frequency.
quantum field theory problems and solutions pdf.
quantum field theory as simply as possible pdf.
quantum field theory for beginners.
quantum field theory books for beginners.
quantum field theory from basics to modern topics.
quantum field theory and critical phenomena pdf.
quantum field theory and critical phenomena.
quantum field theory problems and solutions.
difference between quantum field theory and quantum mechanics.
effective field theory mit.
e field equation.
effective field theory pdf.
fields in quantum field theory.
no-nonsense quantum field theory pdf.
quantum field theory and general relativity.
quantum field theory gravity.
h field equation.
free field hamiltonian.
quantum field theory handwritten notes.
the field quantum physics.
introduction to quantum field theory pdf.
quantum field theory pdf.
quantum field theory for mathematicians pdf.
m field theory.
quantum field theory mit.
no-nonsense quantum field theory a student-friendly introduction.
physics field theory.
philosophy of quantum field theory.
problems with quantum field theory.
quantum field theory vs quantum mechanics.
relativistic quantum field theory pdf.
relative quantum field theory.
quantum field theory research.
quantum field theory simple explanation.
quantum field theory srednicki pdf.
quantum field theory for undergraduates.
unified field theory vs quantum mechanics.
quantum field theory vs general relativity.
quantum field theory weinberg pdf.
quantum field theory experiments.
zee quantum field theory in a nutshell pdf.
quantum field theory zee pdf.
quantum field theory zee.
zee quantum field theory in a nutshell.
field theory physics pdf.
the quantum theory of fields volume 1
how many fields are there in quantum field theory.
quantum field theory for dummies.
Category: mathematics

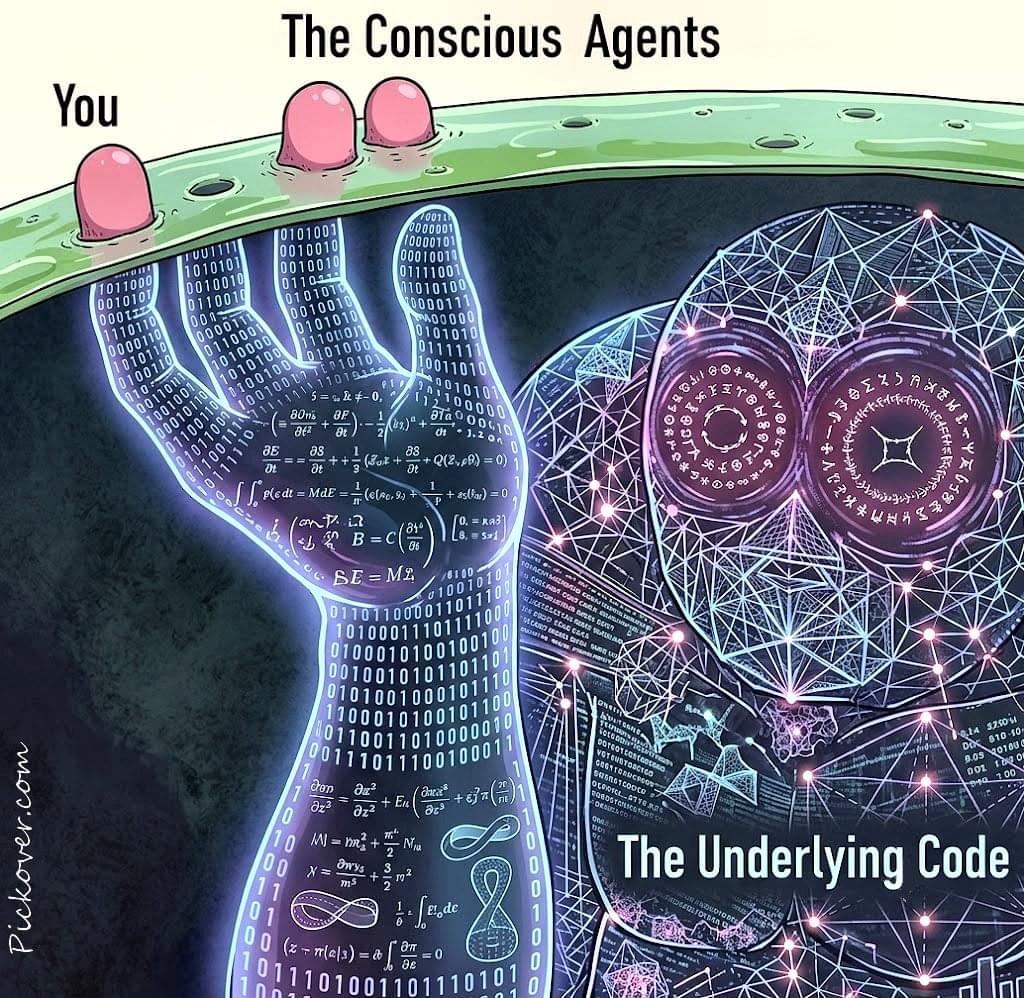
The Rosetta Manifold: How AI Erased the Boundary Between Human Thought and Machine Syntax
The barrier between human thought and machine code is officially gone. 🤯
In my last deep dive, we explored “Vibecoding” and how creators are bypassing traditional development bottlenecks using pure vision. But how does AI actually turn your spoken intent into architecture?
AI doesn’t just use a massive translation dictionary. Instead, it operates in a hidden mathematical geometry known as the Latent Space.
In this invisible architecture, an English phrase and a complex Python script are mapped into the exact same coordinate of pure logic. This triggers a massive paradigm shift called Decision Compression—completely erasing the buggy, high-friction “Telephone Game” of traditional software development by binding your raw idea directly to execution.
If AI completely bypasses the need for manual translation, what happens to traditional coding syntax like Java or C++?
And more importantly, who becomes the ultimate builder in this new paradigm?
Read the full deep dive into the engine of the AI revolution!
Cliff Pickover (@pickover) on X
We aren’t the authors of our thoughts. We’re just the user interface. We look at the universe and see a solid reality. The universe looks at us and sees a line of code. We spend our lives trying to leave a mark on the surface of reality. Oblivious to the fact that our existence is being computed from beneath. We aren’t separate individuals. We’re just the localized tips of a single, massive mathematical architecture.👇
(PDF) Holographic Entanglement-Weighted de Sitter Gravity
🌌 Holographic theory suggests a profound idea: the universe may store information on its boundary, while the spacetime we experience emerges from that information. In this view, gravity is not only a force between masses.
https://doi.org/10.13140/RG.2.2.17062.
It may also be a macroscopic effect of quantum information, especially entanglement, encoded on a cosmic horizon. 🧠✨
A simple way to express this is:
Horizon information → Entanglement → Spacetime geometry.
To describe how efficiently entanglement becomes geometry, we introduce an entanglement-weight field:
Here, W(x) represents the conversion efficiency from holographic entanglement to gravitational geometry.
This modifies the effective strength of gravity:
The secret code behind the universe | Stephen Wolfram
Simple rules. Infinite complexity. Physicist Stephen Wolfram has spent forty years working out the connection. Here’s the short version.
❍ Subscribe to The Well on YouTube: https://bit.ly/welcometothewell.
❍ Up next: Why the answers to big questions are fundamentally unknowable | L.A. Paul • Why the answers to big decisions are funda…
Physicist Stephen Wolfram spent decades running computer experiments on simple rules — not looking for anything grand, just seeing what happened. What he found turned into a model of how the universe works, an explanation for why evolution never gets stuck, and a mathematical argument for why your life can’t be shortcut or predicted by anyone.
Read the full video transcript: https://bigthink.com/videos/the-unive…
❍ About The Well ❍
Do we inhabit a multiverse? Do we have free will? What is love? Is evolution directional? There are no simple answers to life’s biggest questions, and that’s why they’re the questions occupying the world’s brightest minds.

Method for stress-testing cloud computing algorithms helps avoid network failures
This new approach can identify worse-case scenarios that an engineer might miss if they use a traditional method that compares an algorithm against a set of human-designed past test cases. It is also less labor-intensive than other verification tools that require engineers to rewrite an algorithm in a complex mathematical code each time they want to test it.
Instead of needing a mathematical reformulation, the new method reads the algorithm’s source code directly and automatically searches for worse-case scenarios that lead to the highest level of underperformance.
By helping engineers quickly and easily stress-test a networking algorithm before deployment, the method could catch failure modes that might otherwise only appear in a real outage. The technique could also be used to analyze the risks of deploying AI-generated code.
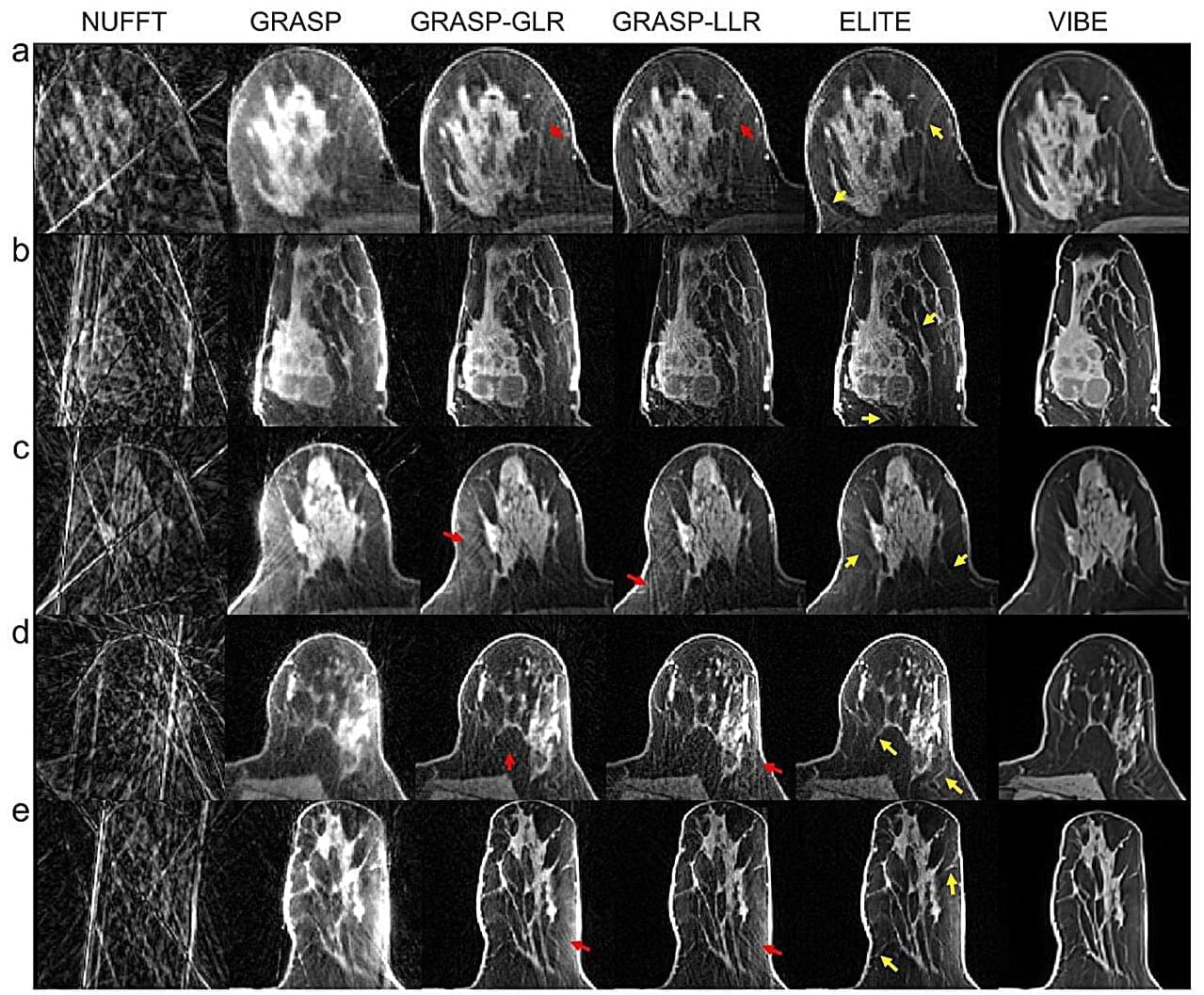
Faster breast MRI—AI unlocks one image per second and sharper tumor tracking
{kind=link}
A group of researchers from the Technion and the United States reports a breakthrough in MRI scanning in a paper published in Nature Communications. The researchers developed an innovative method that accelerates and enhances MRI scans for breast cancer imaging, a disease diagnosed in approximately 2.3 million people each year, most of whom are women.
The new method, called ELITE, combines artificial intelligence with advanced mathematical models, enabling dynamic MRI with unprecedented speed and accuracy. This international study brings together expertise in engineering, MRI physics, artificial intelligence and clinical radiology.
Dr. Eddy Solomon of the Technion’s Faculty of Biomedical Engineering, the paper’s lead author, explains that the study focuses on dynamic MRI, a critical technology in breast cancer diagnosis. Dynamic MRI is used primarily for screening populations at high risk for breast cancer and is characterized by exceptionally high sensitivity, with more than 90% accuracy, compared with approximately 50%–60% for ultrasound and mammography combined. However, MRI technology faces a major challenge: Producing highly detailed images usually requires longer scan times, making it difficult to track the flow of contrast material through the examined tissue.

Physicists Solve a “Quantum-Only” Problem Using an Ordinary Laptop
A problem once touted as requiring a quantum computer has now been solved on a laptop.
Using advanced mathematical techniques and sophisticated software, physicists at the Center for Computational Quantum Physics (CCQ) at the Simons Foundation’s Flatiron Institute and collaborators at Boston University showed that a conventional computer can successfully simulate a notoriously difficult quantum system previously claimed to be beyond the reach of classical computing.
Heisenberg Said Matter Is Made of Forms, Not Objects — Plato Said It 2,300 Years Earlier
Werner Heisenberg (1901–1976) was one of the founders of quantum mechanics — author of the uncertainty principle (1927) and winner of the 1932 Nobel Prize in Physics. He was also among the most philosophically engaged physicists of the century. In his late teens he read Plato’s Timaeus in the original Greek (his father was a professor of Greek), and the dialogue’s central idea stayed with him: that the smallest constituents of matter are not material objects but mathematical forms.
In Physics and Philosophy (1958), Heisenberg argued that modern physics \.
Intelligence Without Brains: A Radical New Idea
What if intelligence doesn’t require a brain? Biologist Michael Levin argues that intelligence is not confined to neurons, but exists on a continuum of goal-directed behavior and problem-solving across a wide range of species and systems. Using a framework he calls the “cognitive light cone,” Levin explores diverse forms of intelligence extending all the way down to the cellular level. His research suggests that cells communicate through electrical networks, enabling them to make collective decisions and adapt to unexpected challenges, evidenced by engineered tadpoles capable of seeing through eyes located on their tails. Levin radically challenges the conventional wisdom even further, proposing that forms of intelligence may extend beyond biology to molecular systems and maybe even the weather.
00:00 What is intelligence?
01:03 The field of diverse intelligence.
01:33 Intelligence at the cellular level.
02:08 The cognitive light cone.
03:01 The intelligence of groups of cells.
03:52 The bioelectric language of cells.
04:20 The mind of the body.
04:23 Cells that solve problems.
05:17 The tadpole experiment.
06:25 The cognitive spectrum.
06:48 Can you train a hurricane?
07:03 A new science of intelligence.
07:28 Beyond human biases.
——–
Quanta Magazine is an editorially independent publication supported by the Simons Foundation. We focus on developments in mathematics, theoretical physics, theoretical computer science and the basic life sciences.
READ free math and science articles on the Quanta website: https://www.quantamagazine.org.
LEARN about the Simons Foundation: www.simonsfoundation.org.
FOLLOW our social channels: