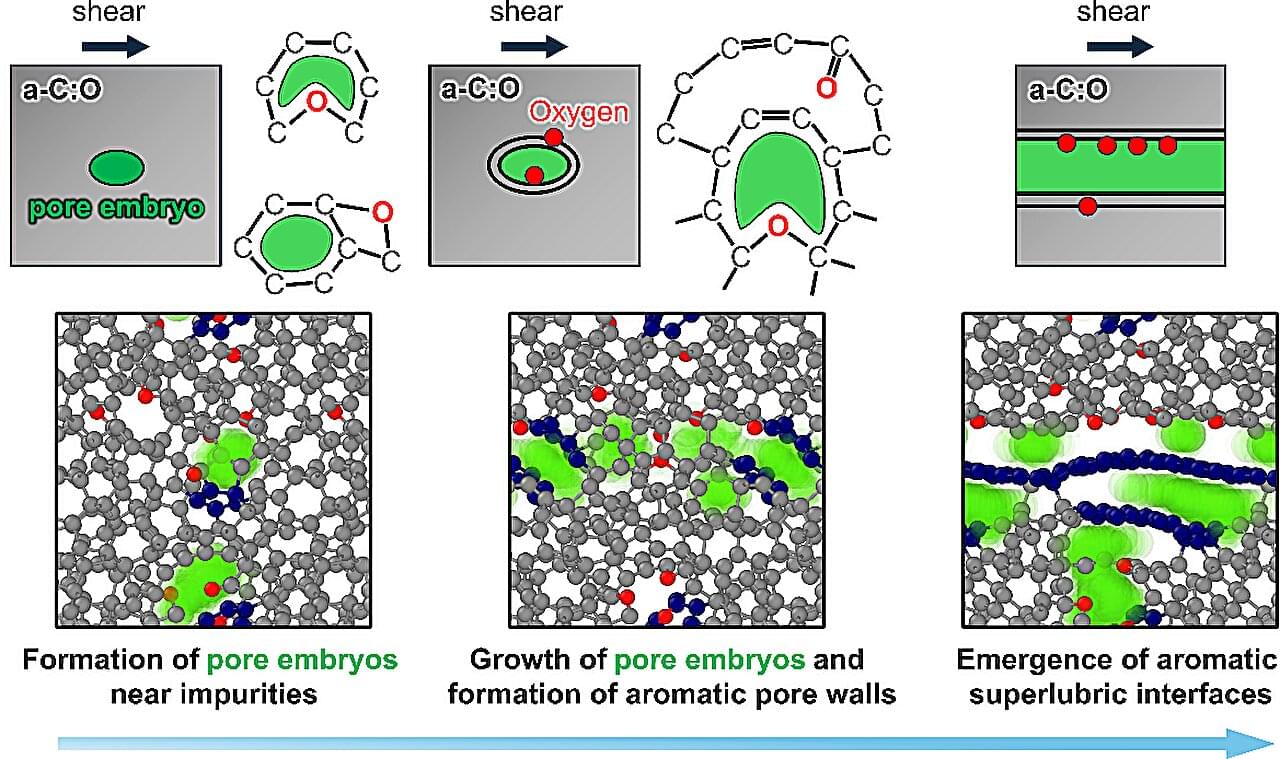
Engineers often treat impurities as a problem to eliminate to improve material performance. But new research from Osaka Metropolitan University and Fraunhofer Institute for Mechanics of Materials IWM suggests that in some cases, a little chemical messiness is exactly what helps materials slide more smoothly. The findings were published in Advanced Science.
When two surfaces slide or rub against each other, friction occurs. While friction is essential for many everyday applications, it also wears down machines, wastes energy and limits the lifespan of moving parts. Therefore, research has focused on achieving superlow friction, or superlubricity, in which surfaces can slide past one another with exceptionally low resistance.
“While graphene-or graphite-like structures are known to enable nearly frictionless sliding, creating and maintaining such structures in practical systems remains challenging,” said Takuya Kuwahara, lecturer at Osaka Metropolitan University’s Graduate School of Engineering and lead author of the study.





{kind=link}