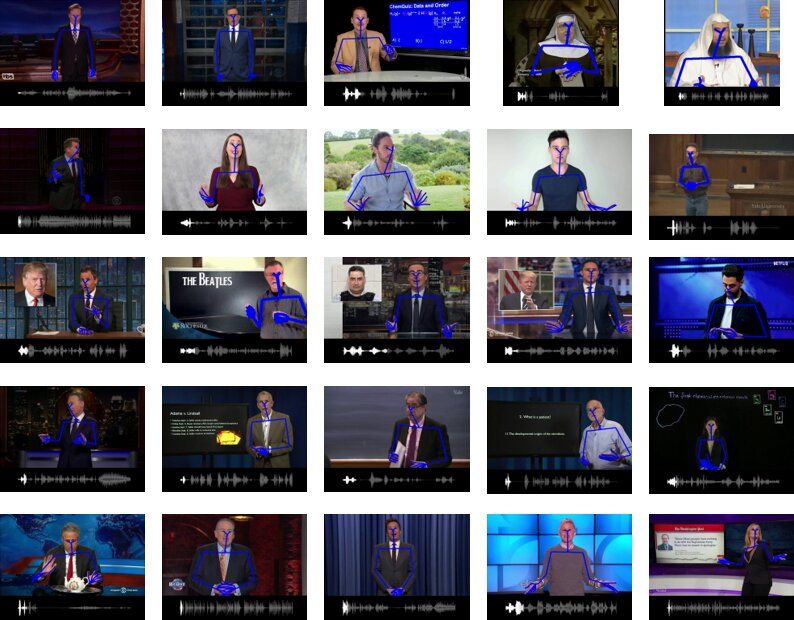
Virtual assistants and robots are becoming increasingly sophisticated, interactive and human-like. To fully replicate human communication, however, artificial intelligence (AI) agents should not only be able to determine what users are saying and produce adequate responses, they should also mimic humans in the way they speak.
Researchers at Carnegie Mellon University (CMU) have recently carried out a study aimed at improving how virtual assistants and robots communicate with humans by generating natural gestures to accompany their speech. Their paper, pre-published on arXiv and set to be presented at the European Conference on Computer Vision (ECCV) 2020, introduces Mix-StAGE, a new model that can produce different styles of co-speech gestures that best match the voice of a speaker and what he/she is saying.
“Imagine a situation where you are communicating with a friend in a virtual space through a virtual reality headset,” Chaitanya Ahuja, one of the researchers who carried out the study, told TechXplore. “The headset is only able to hear your voice, but not able to see your hand gestures. The goal of our model is to predict the hand gestures accompanying the speech.”