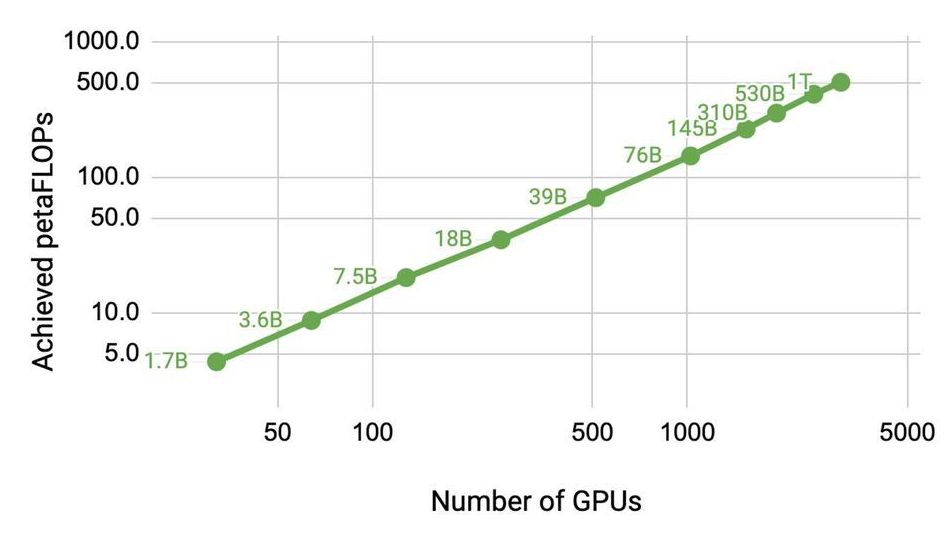
Natural Language Processing (NLP) has seen rapid progress in recent years as computation at scale has become more available and datasets have become larger. At the same time, recent work has shown large language models to be effective few-shot learners, with high accuracy on many NLP datasets without additional finetuning. As a result, state-of-the-art NLP models have grown at an exponential rate (Figure 1). Training such models, however, is challenging for two reasons: