Training efficiency has become a significant factor for deep learning as the neural network models, and training data size grows. GPT-3 is an excellent example to show how critical training efficiency factor could be as it takes weeks of training with thousands of GPUs to demonstrate remarkable capabilities in few-shot learning.
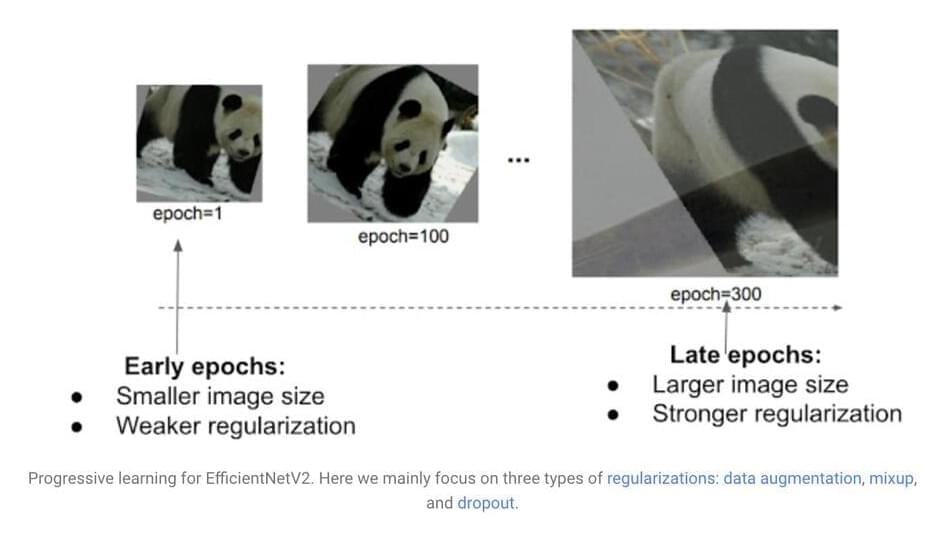
To address this problem, the Google AI team introduce two families of neural networks for image recognition. First is EfficientNetV2, consisting of CNN (Convolutional neural networks) with a small-scale dataset for faster training efficiency such as ImageNet1k (with 1.28 million images). Second is a hybrid model called CoAtNet, which combines convolution and self-attention to achieve higher accuracy on large-scale datasets such as ImageNet21 (with 13 million images) and JFT (with billions of images). As per the research report by Google, EfficientNetV2 and CoAtNet both are 4 to 10 times faster while achieving state-of-the-art and 90.88% top-1 accuracy on the well-established ImageNet dataset.