{kind=link}
Human-like articulated neural avatars have several uses in telepresence, animation, and visual content production. These neural avatars must be simple to create, simple to animate in new stances and views, capable of rendering in photorealistic picture quality, and simple to relight in novel situations if they are to be widely adopted. Existing techniques frequently use monocular films to teach these neural avatars. While the method permits movement and photorealistic image quality, the synthesized images are constantly constrained by the training video’s lighting conditions. Other studies specifically address the relighting of human avatars. However, they do not provide the user control over the body stance. Additionally, these methods frequently need multiview photos captured in a Light Stage for training, which is only permitted in controlled environments.
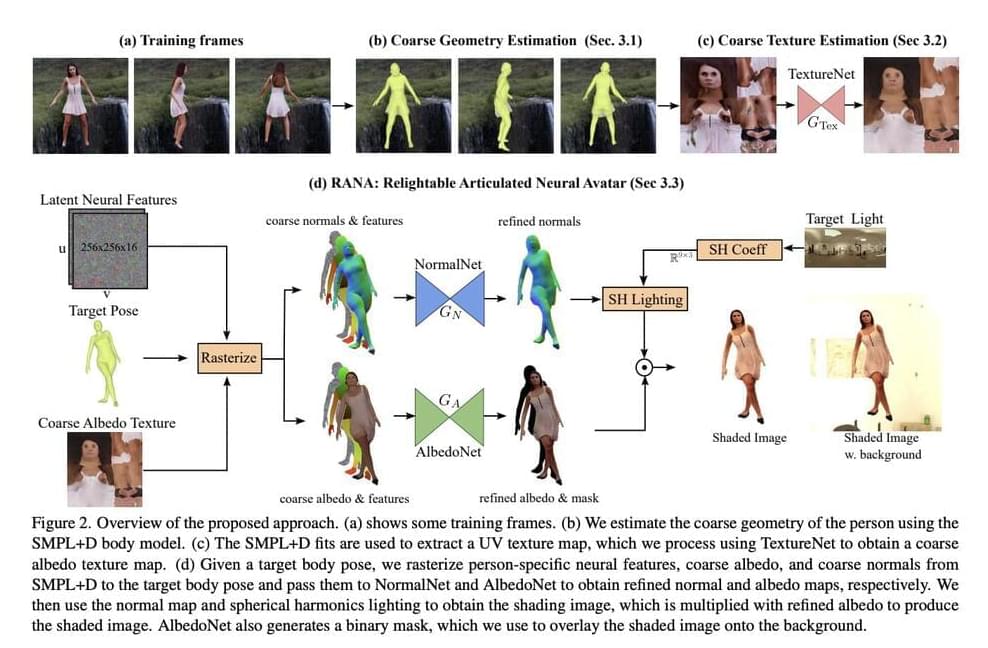
Some contemporary techniques seek to relight dynamic human beings in RGB movies. However, they lack control over body posture. They need a brief monocular video clip of the person in their natural location, attire, and body stance to produce an avatar. Only the target novel’s body stance and illumination information are needed for inference. It is difficult to learn relightable neural avatars of active individuals from monocular RGB films captured in unfamiliar surroundings. Here, they introduce the Relightable Articulated Neural Avatar (RANA) technique, which enables photorealistic human animation in any new body posture, perspective, and lighting situation. It first needs to simulate the intricate articulations and geometry of the human body.
The texture, geometry, and illumination information must be separated to enable relighting in new contexts, which is a difficult challenge to tackle from RGB footage. To overcome these difficulties, they first use a statistical human shape model called SMPL+D to extract canonical, coarse geometry, and texture data from the training frames. Then, they suggest a unique convolutional neural network trained on artificial data to exclude the shading information from the coarse texture. They add learnable latent characteristics to the coarse geometry and texture and send them to their proposed neural avatar architecture, which uses two convolutional networks to produce fine normal and albedo maps of the person underneath the goal body posture.