Chengyi wang*, sanyuan chen*, yu wu*, ziqiang zhang, long zhou, shujie liu, zhuo chen, yanqing liu, huaming wang, jinyu li, lei he, sheng zhao, furu wei.
Microsoft
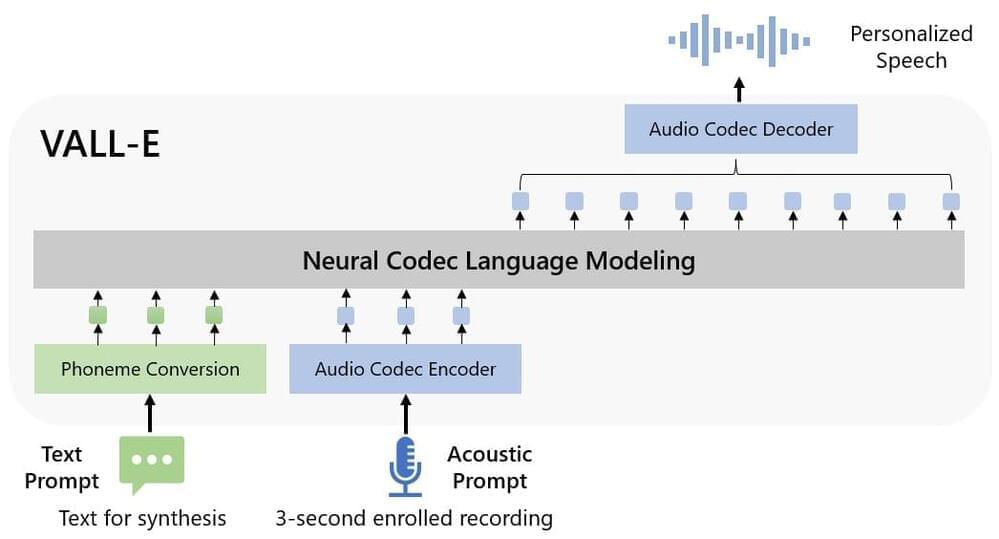
Abstract. We introduce a language modeling approach for text to speech synthesis (TTS). Specifically, we train a neural codec language model (called VALL-E) using discrete codes derived from an off-the-shelf neural audio codec model, and regard TTS as a conditional language modeling task rather than continuous signal regression as in previous work. During the pre-training stage, we scale up the TTS training data to 60K hours of English speech which is hundreds of times larger than existing systems. VALL-E emerges in-context learning capabilities and can be used to synthesize high-quality personalized speech with only a 3-second enrolled recording of an unseen speaker as an acoustic prompt. Experiment results show that VALL-E significantly outperforms the state-of-the-art zero-shot TTS system in terms of speech naturalness and speaker similarity. In addition, we find VALL-E could preserve the speaker’s emotion and acoustic environment of the acoustic prompt in synthesis.