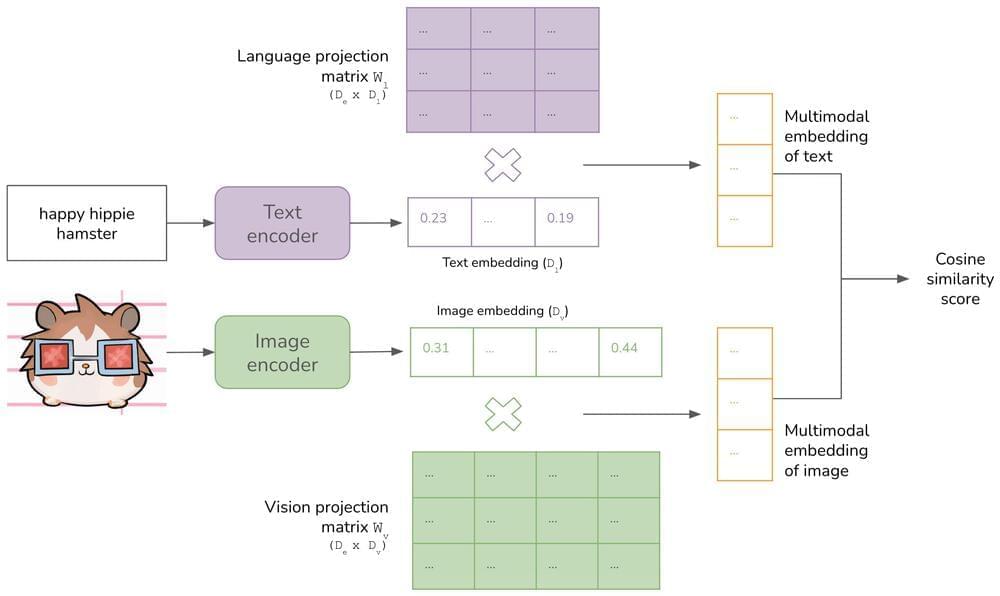
For a long time, each ML model operated in one data mode – text (translation, language modeling), image (object detection, image classification), or audio (speech recognition).
However, natural intelligence is not limited to just a single modality. Humans can read and write text. We can see images and watch videos. We listen to music to relax and watch out for strange noises to detect danger. Being able to work with multimodal data is essential for us or any AI to operate in the real world.
OpenAI noted in their GPT-4V system card that “incorporating additional modalities (such as image inputs) into LLMs is viewed by some as a key frontier in AI research and development.”