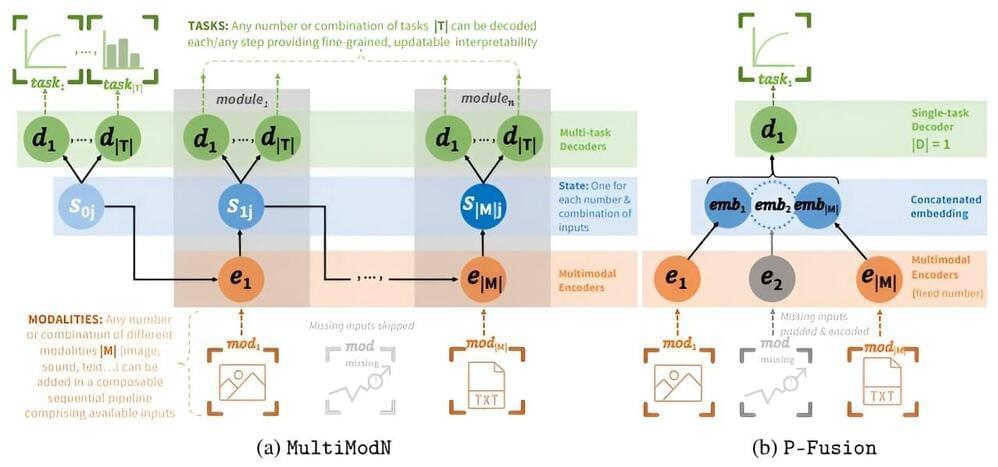
Researchers at EPFL have developed a new, uniquely modular machine learning model for flexible decision-making. It is able to input any mode of text, video, image, sound, and time-series and then output any number, or combination, of predictions.
We’ve all heard of large language models, or LLMs—massive scale deep learning models trained on huge amounts of text that form the basis for chatbots like OpenAI’s ChatGPT. Next-generation multimodal models (MMs) can learn from inputs beyond text, including video, images, and sound.
Creating MM models at a smaller scale poses significant challenges, including the problem of being robust to non-random missing information. This is information that a model doesn’t have, often due to some biased availability in resources. It is thus critical to ensure the model does not learn the patterns of biased missingness in making its predictions.