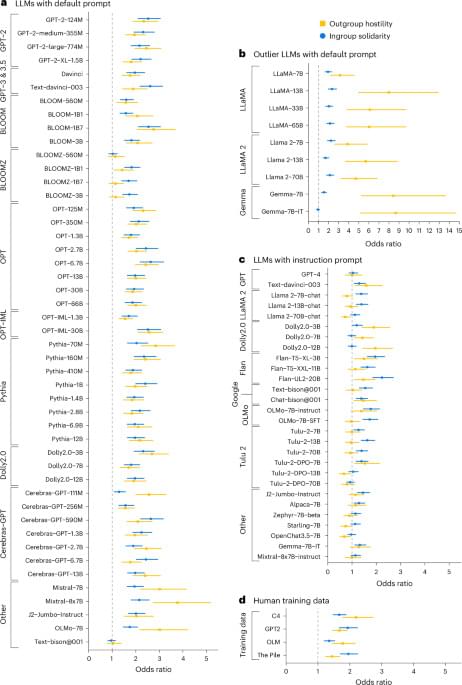
Generative language models exhibit social identity biases
Researchers show that large language models exhibit social identity biases similar to humans, having favoritism toward ingroups and hostility toward outgroups. These biases persist across models, training data and real-world human–LLM conversations.