But deep learning has a massive drawback: The algorithms can’t justify their answers. Often called the “black box” problem, this opacity stymies their use in high-risk situations, such as in medicine. Patients want an explanation when diagnosed with a life-changing disease. For now, deep learning-based algorithms—even if they have high diagnostic accuracy—can’t provide that information.
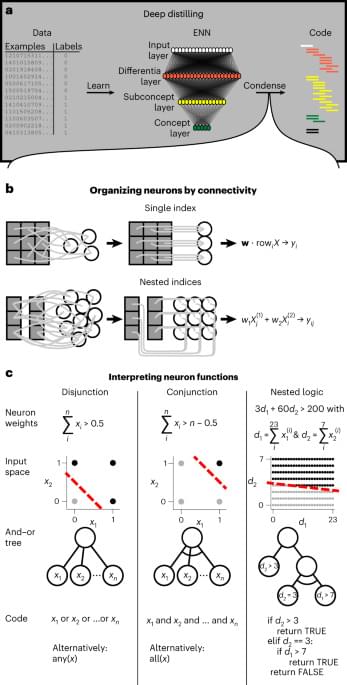
To open the black box, a team from the University of Texas Southwestern Medical Center tapped the human mind for inspiration. In a study in Nature Computational Science, they combined principles from the study of brain networks with a more traditional AI approach that relies on explainable building blocks.
The resulting AI acts a bit like a child. It condenses different types of information into “hubs.” Each hub is then transcribed into coding guidelines for humans to read—CliffsNotes for programmers that explain the algorithm’s conclusions about patterns it found in the data in plain English. It can also generate fully executable programming code to try out.