Are you considering using AI to help improve your organization? Here’s how AI is accelerating innovation.
Category: innovation – Page 7


Microsoft can now store data for 10,000 years on everyday glass thanks to laser breakthrough
Breakthrough improvements to Microsoft’s glass-based data-storage technology mean ordinary glassware, such as that used in cookware and oven doors, can store terabytes of data, with the information lasting 10,000 years.
The technology, which has been in development under the “Project Silica” banner since 2019, has seen steady improvements, and scientists outlined the latest innovations today (Feb. 18) in the journal Nature.
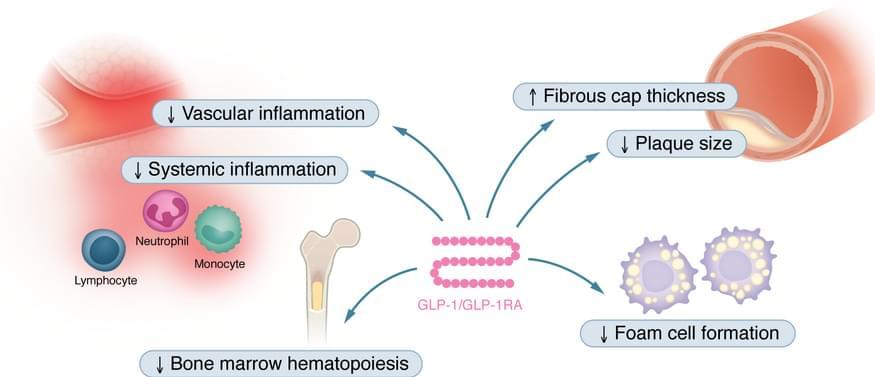
Abstract: GLP-1 and the cardiovascular system
As part of JCI’s Review Series on Clinical Innovation and Scientific Progress in GLP-1 Medicine Florian Kahles, Andreas L. Birkenfeld, & Nikolaus Marx summarize the effects of GLP-1 and GLP-1RAs in the cardiovascular system as well as clinical data of GLP-1RAs in individuals with cardiovascular disease or in those at high risk.
1Department of Internal Medicine I, University Hospital Aachen, RWTH Aachen, Aachen, Germany.
2German Center for Diabetes Research (DZD), Neuherberg, Germany.
3Department of Internal Medicine IV, Diabetology, Endocrinology and Nephrology, Eberhard-Karls University Tübingen, Tübingen, Germany.


Levi’s® Tests 3D Printing Technology
Over 50 years ago, the classic Levi’s® Trucker jacket was introduced. But we are not one to rest on past accomplishments.
Now, the brand is turning to futuristic modes of innovation in manufacturing, pioneering a new approach in denim design.
Fast Company joined Levi’s® Head of Global Product Innovation, Paul Dillinger, at the Autodesk Pier 9 Workshop in San Francisco to witness how Levi’s® has been experimenting with 3D printing, creating digital renderings of the denim jacket which is essentially a shell of what the “real” thing could look like.
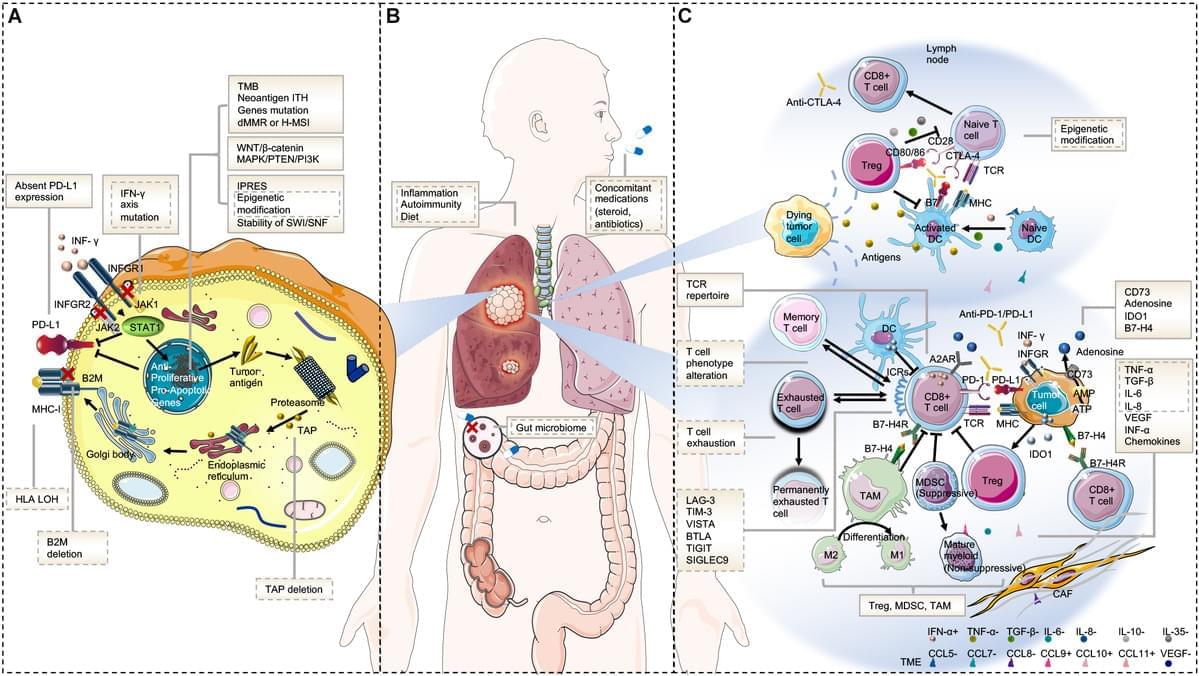
Issues and Challenges in NSCLC Immunotherapy
Immunotherapy has revolutionized lung cancer treatment in the past decade. By reactivating the host’s immune system, immunotherapy significantly prolongs survival in some advanced lung cancer patients. However, resistance to immunotherapy is frequent, which manifests as a lack of initial response or clinical benefit to therapy (primary resistance) or tumor progression after the initial period of response (acquired resistance). Overcoming immunotherapy resistance is challenging owing to the complex and dynamic interplay among malignant cells and the defense system. This review aims to discuss the mechanisms that drive immunotherapy resistance and the innovative strategies implemented to overcome it in lung cancer.
The discovery of the immune checkpoint inhibitors (ICIs), represented by the monoclonal antibodies that block cytotoxic T−lymphocyte−associated protein 4 (CTLA-4), programmed death protein 1 (PD-1), and programmed death protein ligand 1 (PD-L1), has revolutionized the therapeutic landscape of lung cancer. The significant survival benefit derived from ICI-containing treatment has established it as the mainstay first-line therapy in patients with advanced or locally advanced non-small cell lung cancer (NSCLC) and extensive small-cell lung cancer (SCLC). Unprecedented long-term clinical benefit or even, in some cases, a complete recovery has been witnessed in lung cancer, particularly in patients with high PD-L1-expressing tumors (1– 3). Currently, investigations are under way aimed at integrating immunotherapy in the treatment of early-stage lung cancer.
However, most patients with NSCLC develop primary resistance during ICI monotherapy and only 15 to 20% achieve partial or complete response (3). Acquired resistance also occurs in initially responding patients with advanced NSCLC treated with ICIs, after a median progression-free survival (PFS) of 4–10 months (4– 9). The mechanisms of resistance to immunotherapy are not yet fully understood, and methods to overcome them must be developed. Herein, we discuss the pathways driving resistance to immunotherapy in lung cancer to help clinicians in their current practice, as well as identify future research priorities and treatment strategies.

Rethinking Memory Mechanisms of Foundation Agents in the Second Half: A Survey
The research of artificial intelligence is undergoing a paradigm shift from prioritizing model innovations over benchmark scores towards emphasizing problem definition and rigorous real-world evaluation. As the field enters the “second half,” the central challenge becomes real utility in long-horizon, dynamic, and user-dependent environments, where agents face context explosion and must continuously accumulate, manage, and selectively reuse large volumes of information across extended interactions. Memory, with hundreds of papers released this year, therefore emerges as the critical solution to fill the utility gap. In this survey, we provide a unified view of foundation agent memory along three dimensions: memory substrate (internal and external), cognitive mechanism (episodic, semantic, sensory, working, and procedural), and memory subject (agent- and user-centric). We then analyze how memory is instantiated and operated under different agent topologies and highlight learning policies over memory operations. Finally, we review evaluation benchmarks and metrics for assessing memory utility, and outline various open challenges and future directions.