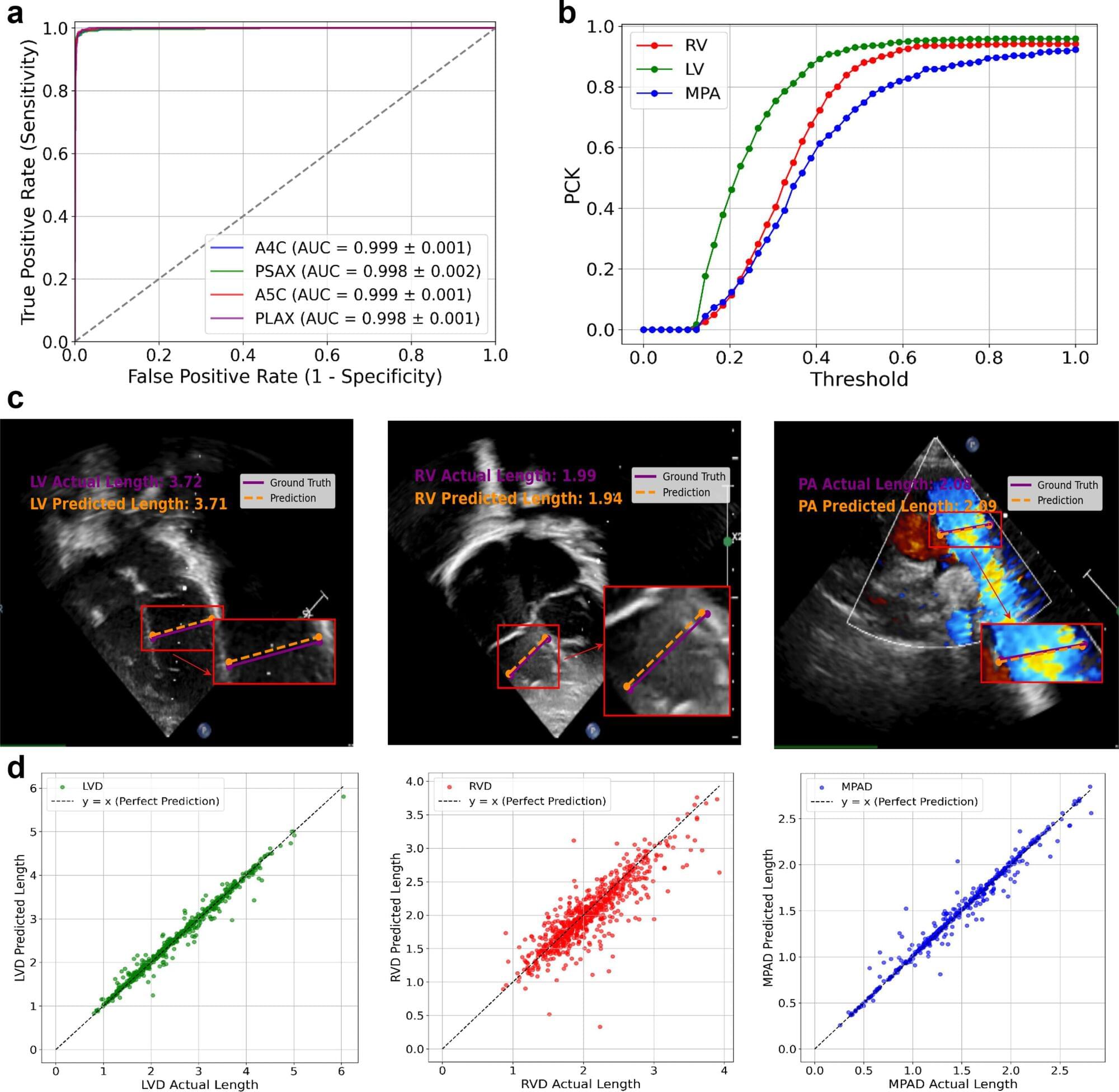
Every echocardiogram is a moving story. For a baby born with a complex heart condition, the gray and black images on the ultrasound screen can influence some of the earliest and most important decisions a medical team makes: What exactly is wrong with the heart? How urgent is surgery? What should doctors watch for after repair?
In our recent work, we focused on tetralogy of Fallot, often shortened to TOF. It is one of the most common cyanotic congenital heart defects. The condition involves several structural abnormalities of the heart, and many children with TOF need careful evaluation, surgery and long-term follow-up. The research is published in the journal eBioMedicine.
Echocardiography is central to that process. It is widely used, noninvasive and rich in clinical information. But it is also demanding. Clinicians must identify the correct views, interpret moving images, measure small cardiac structures, and combine these pieces of information with the patient’s clinical course. Even experienced clinicians can face heavy workloads, and interpretation can vary between observers.