Natural language processing (NLP) has entered a transformational period with the introduction of Large Language Models (LLMs), like the GPT series, setting new performance standards for various linguistic tasks. Autoregressive pretraining, which teaches models to forecast the most likely tokens in a sequence, is one of the main factors causing this amazing achievement. Because of this fundamental technique, the models can absorb a complex interaction between syntax and semantics, contributing to their exceptional ability to understand language like a person. Autoregressive pretraining has substantially contributed to computer vision in addition to NLP.
In computer vision, autoregressive pretraining was initially successful, but subsequent developments have shown a sharp paradigm change in favor of BERT-style pretraining. This shift is noteworthy, especially in light of the first results from iGPT, which showed that autoregressive and BERT-style pretraining performed similarly across various tasks. However, because of its greater effectiveness in visual representation learning, subsequent research has come to prefer BERT-style pretraining. For instance, MAE shows that a scalable approach to visual representation learning may be as simple as predicting the values of randomly masked pixels.
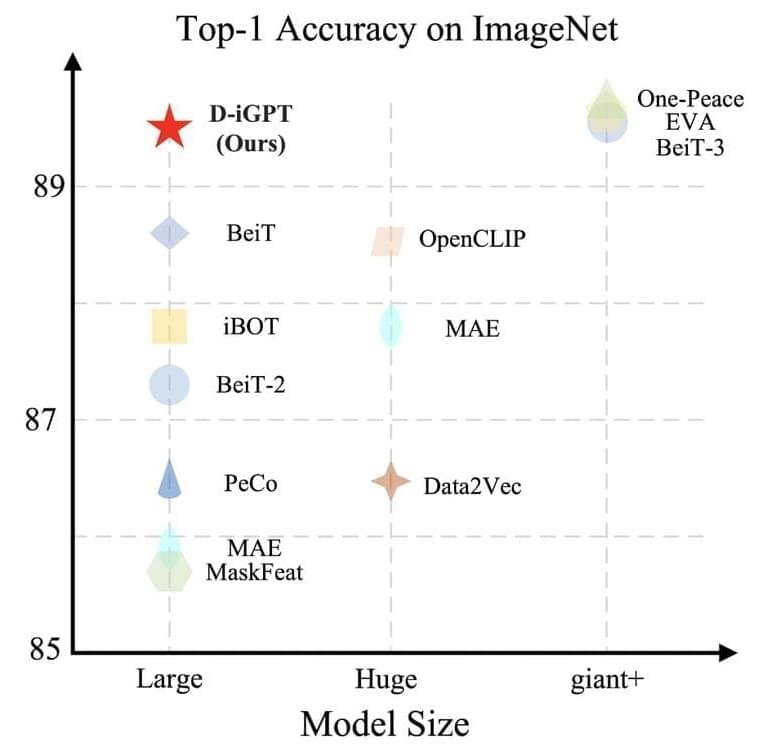
In this work, the Johns Hopkins University and UC Santa Cruz research team reexamined iGPT and questioned whether autoregressive pretraining can produce highly proficient vision learners, particularly when applied widely. Two important changes are incorporated into their process. First, the research team “tokenizes” photos into semantic tokens using BEiT, considering images are naturally noisy and redundant. This modification shifts the focus of the autoregressive prediction from pixels to semantic tokens, allowing for a more sophisticated comprehension of the interactions between various picture areas. Secondly, the research team adds a discriminative decoder to the generative decoder, which autoregressively predicts the subsequent semantic token.